接上回说,咱前面在上一期《干货周记:趣说“语音降噪”(三)(番外篇19)》中,有简单介绍了DNN、CNN、RNN、GRU、GAN、CRN等网络架构,这些也是咱们这篇文章讨论的基础。
与依赖统计的“传统降噪”不同,AI降噪是数据驱动的,其核心也是是如何更巧妙、更高效地用类似上述的架构,实现“强降噪+高保真”的效果。
拜算力所赐,各种AI降噪模型虽然年龄不大,但却一直都在花样进化中,效果也是肉眼可见的一年比一年好。更有趣的是,如果咱单看它的基础计算,基本都是些朴素的乘加运算,和非线性处理,几乎就是小学生级别的计算,而给它们一上量(巨量),“神迹”还真就出现了。
当前主流的AI降噪模型,主要有两种实现手段:Mask(基于掩蔽)或者Mapping(基于映射)。
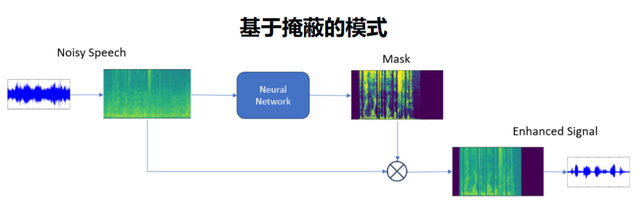
基于掩蔽Mask的方式,AI的最终输出是个“估计滤波器”,用它对带噪语谱进行滤波,再反变换得到干净的时域信号即可。一般而言,它不会引起信号的明显失真,实现起来也更灵活,用的也比较多。
值得注意的是,这类算法估计的滤波器,对幅度通常有抑制作用(幅度系数在0~1之间),所以它在干掉噪声的同时,也可能会影响到有用信号的幅度,语音能量比较弱时,降完噪可能会产生语谱“黑洞”。
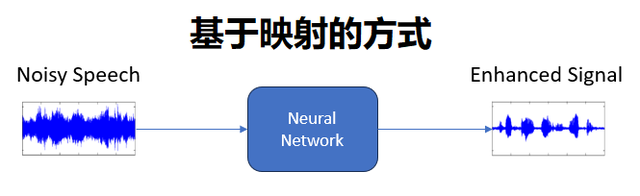
基于映射的方式,则是直接输出干净的时域信号,有点儿"端到端"那意思。这种方式有点像“脑补”法,通过海量神经网络单元,再生语音信号。
它的好处是,可解决相位重构等时间相关问题。但它也可能会引入伪像等问题,容易不稳定,因此它不如Mask方式普遍。
AI模型发展的草蛇灰线
早期基于单CNN的AI降噪,虽说参数少,局部特征抓取也不错,但缺乏记忆力,搞不定长序列数据的应用,效果自然也好不到哪儿去。
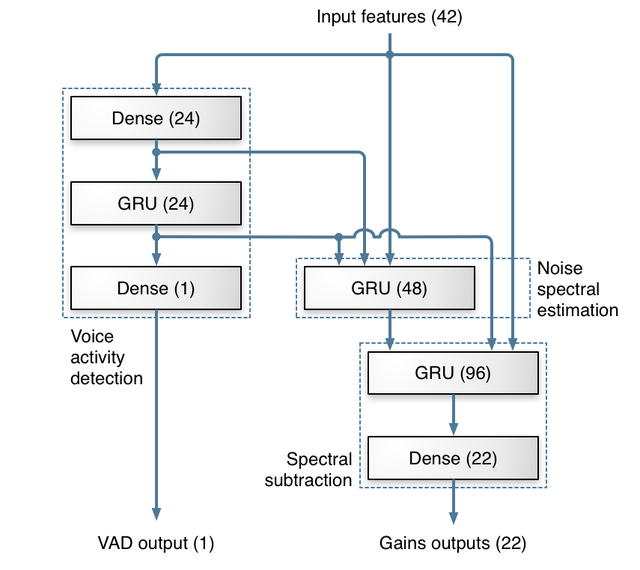
单基于RNN的模型也好不到哪儿去,比如2017年的RNNoise,其基本流程大致如下:
不慌,模型在迭代。在CNN的基础上,加入LSTM,就能做长序列建模了。如此,模型既能提取信息特征,又具备了记忆力。此时的幅度谱估计已经很不错了,但相位信息还没加进来。
还记得前面提到的CRN吗?它在编码器和解码器之间,加入了几个堆叠的LSTM做记忆建模,但它只用了幅度信息,后面用iSTFT重建时域信息时,它用的是原始带噪信号的相位。
在高信噪比场景下,这倒也无妨,因为此时纯净语音与带噪信号的相位差,确实不大。而在中低信噪比场景下,再这么做,就不讲究了。
不慌,模型还在迭代。“幅度估计”做得足够好之后,“相位估计”很快就被提上了日程。换言之,实数神经网络已经不够了,咱得引入复数谱优化了。实部与虚部,幅度与相位,一个都不能少。
FRCRN就解决了这个问题,它在原来的基础上,引入了FSMN(前馈序列记忆网络),结合复数域网络运算,实现了同时对语音幅度和相位的增强(DCCRN也类似)。此时的AI降噪效果,已经很优秀了。

听上去计算很复杂,对吧?一个FRCRN的相关算力需求案例,供参考如下:运算量:24.6GFLOPS(12.30 GMACS),参数量:10.27M,延时:30ms。
这就天衣无缝了吗?当然不。复数谱优化,可没那么简单,因为一不留神,就会带来幅度偏差,咋办?
不慌,模型一直在迭代。
哪里有压迫,哪里就有反抗。为了应对这一挑战,“多阶段优化”出现了。多阶段处理的核心在于,分而治之,渐进式优化。实现方式也有多种,比如:级联网络、分频段处理等。

举例:DeepFilterNet3:第一阶段(轻量CNN)快速降噪,第二阶段(复数RNN)细化频谱,包括相位优化。再比如:MIMO-Unet+:多个U-Net级联,逐步分分频段处理。如此,可尽量保证在优化复数谱的同时,降低幅度谱估计误差。目前我体验过最好的demo效果,就在这个级别。还有一些类似的,如下:

这下看上去就更不错了,你真以为这就完美了吗?No,前面还有误差累积、计算量增加的其他问题。
不慌,模型的迭代从未停止。相应的,“交叉阶段监督”、“特征融合”、“模型蒸馏”这些新招,一一上场迎战...
到此为止,这些AI降噪模型们,貌似无所不能。但天下没有免费的午餐,就像3A大作吃显卡一样,AI降噪的炫酷是需要代价的。这个代价就是:钱、算力和资源。俩字:氪金。
商业社会中,永远没有最好的方案,只有最适合的选择。无论传统降噪模型,还是各式各样的AI降噪模型,都有其用武之地。
传统降噪模型,算得快,资源少,但真实世界的复杂性(如直播喷麦,小孩哭喊,楼上装修)往往令它头疼。AI降噪,在处理非稳态噪声、保持语音质量和环境适应性有明显优势,但处理延迟和对算力/资源的大胃口,又时常让人囊中羞涩。总之,续航、成本、效果和延迟等都需平衡考虑。

对一些产品,“传统降噪”可能依然是香饽饽。对另一些产品,“AI降噪”则是必经之路。而对没那么富裕的端侧产品,通常会优选小参数模型,如果还达不到预期,有时甚至还会将大模型蒸馏、剪枝后再塞进来。
其实更多时候,会需要双方共同参与,大家各自负责自己擅长的部分。让“传统降噪”先处理常见可预测噪声,让“AI降噪”来处理非稳态噪声等“疑难杂症”,让“声学降噪”逼近物理极限...这种思想,和AI模型中的“多阶段处理”很类似。
比如Zoom中,貌似就用到了“级联轻量模型”(如RNNoise + DeepFilterNet3),阶段1用RNNoise快速降噪(10ms)。阶段2用DeepFilterNet3做精细修复(20ms)。
BTW,其实很多“AI降噪”模型,本身就有受“传统降噪”的启发,比如前面提到的RNNoise,它是基于谱减法的思路,将降噪分为VAD,噪声特性估算和去噪三个部分,简直就是“谱减法”的AI继承人。Roy觉得:RNNoise之于谱减法,就像IIR之于模拟滤波器。
仔细想想,汽车智能驾驶算法也类似。借用地平线余凯的话:要用传统规则算法守住下线,用端到端提升上限。

End
Roy个人观点,仅供参考。
如果你对数码产品、英语学习和励志成长也感兴趣,也可关注各平台上的同名视频账号:微博、抖音、视频号,B站、小红书:科技朋克Roy,知乎:Roy
之前相关文章一览:
干货周记:趣说“语音降噪”(一)(番外篇17)
干货周记:趣说“语音降噪”(二)(番外篇18)
干货周记:趣说“语音降噪”(三)(番外篇19)

